The What is EDI article introduced the basic building blocks of EDI documents -EDI interchange, EDI group, EDI transaction, EDI separators, and EDI version. This article will delve into the structure of EDI transactions.
What is EDI Translator?
An EDI Translator is software that analyzes the string of symbols in an EDI file, adhering to the rules outlined by the EDI standard.
The EDI translator outputs a data structure either in a native programming language, like the C# POCO in EDI Tools for .NET, or in XML/JSON. Some EDI translators produce records in a predefined database structure. Regardless of the exact shape of the output, the goal is to convert the cryptic contents of an EDI file to a structure that:
- Is convenient to be manipulated programmatically
- Conforms to the rules of the EDI standard
EDI Translator is bi-directional, e.g. it should also be able to take as input either a programming language instance, as the C# POCO in EDI Tools for .NET, or other such as XML/JSON/database records, and generate EDI files that adhere to the EDI standard.
EDI Tools for .NET supports both translating to and from EDI files and can be used with all types of input/output structures - C# POCO, XML, JSON, and database.
EDI Format
An EDI transaction is comprised of all segments between the transaction's header and trailer, e.g. ST and SE for X12, or UNH and UNT for EDIFACT, including the header and the trailer. EDI transactions (or messages) represent the actual payload of the business data defined by the EDI standard such as an invoice, a medical claim, or a purchase order.
EDI standards govern the content and the format of EDI transactions and are distributed by what is commonly known as the EDI implementation guideline (or just EDI guideline, EDI spec, EDU rule, or EDI mapping).
Example of X12 implementation guideline, in a tabular format:

Example of EDIFACT implementation guideline, in a tree format:

EDI implementation guidelines stipulate the exact format for EDI transactions, such as an invoice or medical claim. From a programmer’s perspective, they govern the following:
- The blocks of segments grouped together and known as loops (X12) or groups (EDIFACT).
- The sequence and positions at which segments or loops can appear.
- The number of times a segment or a loop can repeat at the same position.
- Whether a segment or a loop is mandatory or optional.
The examples above reveal the main problem when it comes to EDI guidelines - they are in text, picture, or PDF format. This is intended for humans and not machines, however, it is the machines that will be translating EDI files.
So, how to tell a machine what the implementation guideline dictates?
As mentioned in the What is EDI article, there are a few main meta-formats in use today, IBM uses SEF, Microsoft uses XSD, EDI Tools for .NET uses .NET attributes and C# classes, etc., and a multitude of incompatible vendor-specific and proprietary scripts and languages.
EDI Tools for .NET offers the best of all possible solutions - EDI templates. It is best because with EDI templates you can represent EDI guidelines with:
- C# .NET
- JSON
- XML
- Database
EDI templates are simple C# classes extended with EDI Tools for .NET attributes and base classes. No extra technologies or software tools are required, only .NET Core or .NET Framework.
From now on, we'll assume that all EDI guidelines can be represented with EDI templates, and EDI Tools for .NET converts EDI transactions to instances of those EDI templates, and vice versa.
Example of implementation guideline, in EDI template format:
EDI Parser
EDI parsers transform the linear structure of EDI documents into the hierarchical structure of EDI standards. EDI was one of the first attempts to automate the processing of large volumes of data. The particular EDI formatting is a way to compress any data at the source and to provide the instructions (the EDI guideline) to decompress it at the destination unambiguously.
It's like the data is encrypted according to the EDI standard rules, and one can only decrypt it if he follows those rules. They always go hand in hand - the EDI document (the encrypted data) and the EDI rule (the decryption key).
EDI parsers analyze the contents of EDI documents by first identifying each EDI segment, and then working out if it appears in the right sequence according to the guideline.
EDI segments
EDI segments are identified with their segment tags or segment IDs, e.g. the tag of the ST segment is ST. The tag of the UNH segment is UNH. The tag is defined as all characters from the beginning of the segment until the first occurrence of the data element separator.
Segment tags are usually comprised of 3 characters (sometimes 2 characters but never more than 3 or less than 2).
EDI loops
EDI loops (or groups or blocks of segments) are identified by their first segment, also known as the trigger segment. This segment is always mandatory for the loop and can repeat only once.
A repetition of the trigger segment means that the whole loop is repeated. Usually, loops in X12 are named after the trigger segment, e.g. ‘NM1 Loop’. Loops in EDIFACT are enumerated as GR1, GR2, etc.
EDI transactions
The designer of EDI formats must ensure that they describe each transaction unequivocally. For example, the following EDI format has an ambiguous sequence of BEG segments at position 2 and 3:

It is unclear to which BEG from the two should the BEG segment from the transaction below be mapped to:
ST*837*0021*005010X222A1~
BEG*0019*00*244579*20061015*1023*CH~
SE*43*0021~The same logic applies if there was an optional segment in between the BEGs etc. The point is that EDI formats must be properly designed.
Parsing EDI files
Parsing EDI means that each segment in an EDI transaction can be uniquely mapped to a segment in its corresponding EDI format.
The parser compares segments from the EDI file to segments from the EDI guideline to find a match. It compares the segments by their ID and sometimes, the EDI codes in the first two data elements of that segment, e.g. BEG*0019 and BEG*0020 can refer to two different segments, both with BEG as the ID, but with different EDI codes on one or more data elements.
EDI Tools for .NET uses a Depth First Search (DFS) algorithm to search for and match EDI segments. DFS traverses the tree (EDI template) by starting from the root (ST or UNH) and then explores the branches, e.g., if a match was found to a trigger segment, then the search continues a level down before backtracking.
DFS means that if we have the following EDI template with two segments with the same tag NM1 but at different levels:
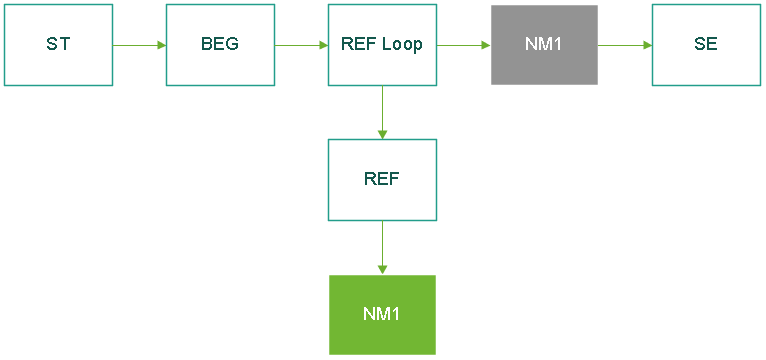
The following EDI transaction:
ST*837*0021*005010X222A1~
BEG*0019*00*244579*20061015*1023*CH~
REF*G2*KA6663~
NM1*QC*1*SMITH*TED~
SE*43*0021~
NM1 will be parsed to the green NM1 because there is a REF segment which is the trigger segment for the REF Loop. Trigger segments play the role of switches to alternate the search path.
ST*837*0021*005010X222A1~
BEG*0019*00*244579*20061015*1023*CH~
NM1*QC*1*SMITH*TED~
SE*43*0021~
NM1 will be parsed to the grey NM1 because there is no REF segment to tell the parser to look down the loop, and the parser carries on and searches forward instead.
I’ll leave out the details of Depth First Search implementation because it is not the premise of this article. The important thing is the DFS fits nicely into parsing EDI and is what EDI Tools for .NET uses to translate EDI files.
Bad Use Case
Let's assume that we have the following common use case:
As a user I want to be able to parse EDI files and then to save the data from the files to a database.
The diagram below describes the general flow by using EDI software that does not offer EDI templates, e.g. that is not EDI Tools for .NET. The EDI rules (or the format specification as governed by the EDI standard) are not represented with EDI templates:

The main drawbacks are:
-
The EDI rules must be handled separately
Additional software and processes are required to maintain, store and resolve/load EDI rules, which add extra steps and complexity to the total cost of ownership of handling the EDI translator.
-
Negative performance impact
The parser will read data from both the EDI file and the EDI rule storage, which is likely to be another file. That's at least two separate instances in memory. The EDI file instance must be transposed to the EDI rule instance, which requires a third in-memory instance.
-
The output structure is not a C# POCO
Depending on the type of output it can be XML, JSON, database, etc., however, not a C# POCO. In order to make any use of it, an additional technique must be involved, such as XML or JSON serializers, or a database access component, rather than simply manipulating a .NET instance and map it to the downstream applications.
The diagram highlights an important fact - integrating with a trading partner using EDI is no different than integrating with a trading partner that is not using EDI. All the boxes would have still been applicable, only named differently.
What we see today is that companies still maintain separate integration channels for EDI and non-EDI, which is a waste of resources. EDI Tools for .NET offers an elegant solution to overcome these needless silos.
Good Use Case
Let's go back to the use case above. If we include EDI Tools for .NET and represent all EDI rules with EDI templates, the diagram would change to:
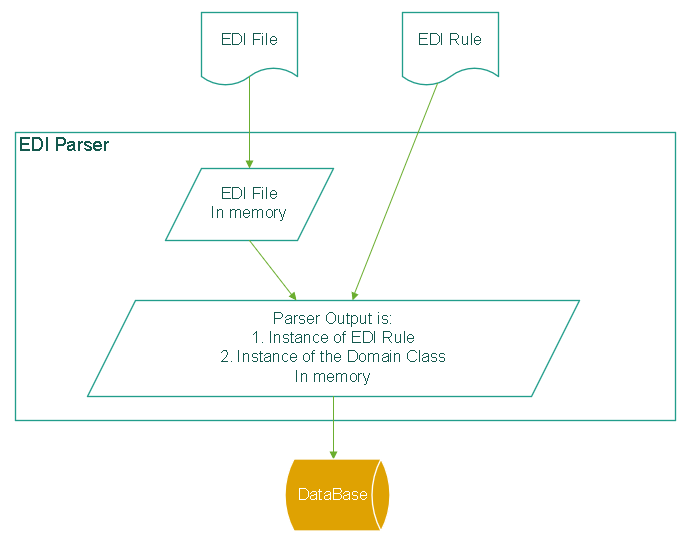
The main benefits are:
-
The EDI rules are handled with EDI templates
No extra software or technology is required to represent EDI rules. EDI templates are simple C# classes that are infinitely configurable and align well with any software architecture.
-
Massive performance gain
The parser will read data from the EDI file only and will create an in-memory instance of the EDI template, which was built into a .NET assembly.
-
The output structure is a C# POCO
The output is a C# POCO. It can be mapped to any downstream application, serialized to XML or JSON, and saved to a database by using only the built-in functionality in .NET, not requiring extra steps, technologies or techniques.
Next Steps
EDI Tools for .NET offers a powerful EDI translator that can be configured around EDI templates to support any EDI implementation guideline, regardless of whether it adheres to an EDI standard or is partner-specific.
You can try the best EDI translator:
To learn more about EDI head on to our What is EDI article or The state of in-house EDI article.
Comments
0 comments
Please sign in to leave a comment.